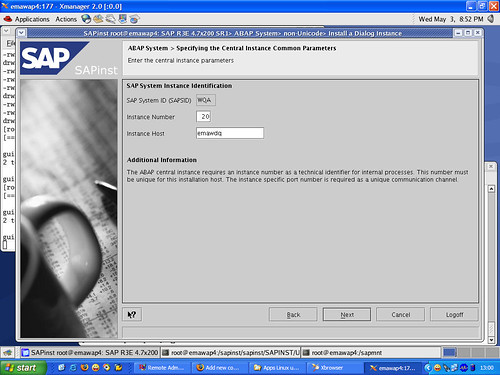
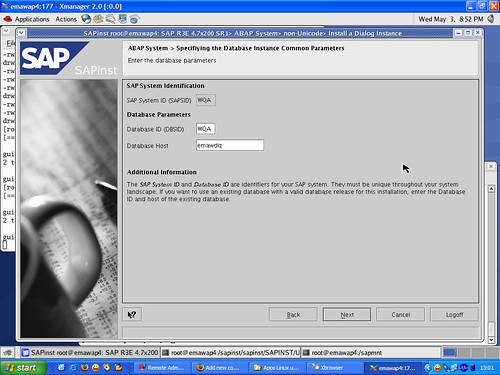
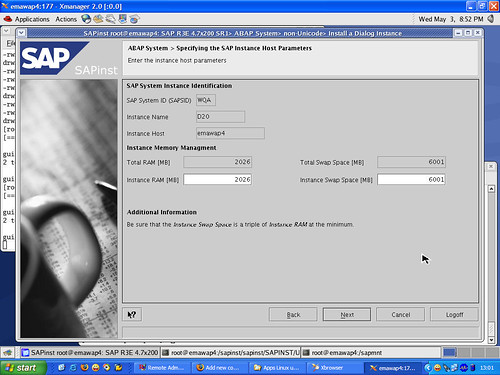
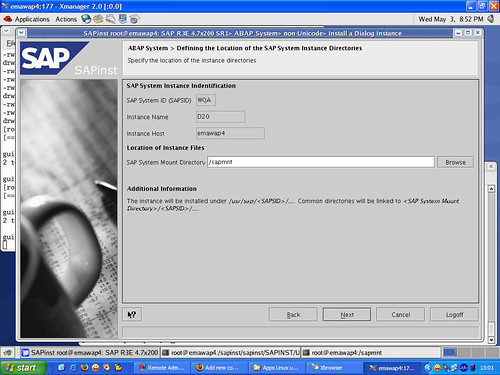
Suppose I’m visiting a web site. I right-click on one of the navigation links and select to open the link in a new window. What should happen? If I’m like most users, I expect the new page to have the same content as if I had clicked the link directly. The only difference should be that the page appears in a new window. But if your web site is a single-page application (SPA), you may see weird results unless you’ve carefully planned for this case.
Recall that in an SPA, a typical navigation link is often a fragment identifier, starting with a hash mark (#). Clicking the link directly does not reload the page, so all the data stored in JavaScript variables are retained. But if I open the link in a new tab or window, the browser does reload the page, reinitializing all the JavaScript variables. So any HTML elements bound to those variables will display differently, unless you’ve taken steps to preserve that data somehow.

There’s a similar issue if I explicitly reload the page, such as by hitting F5. You may think I shouldn’t ever need to hit F5, because you’ve set up a mechanism to push changes from the server automatically. But if I’m a typical user, you can bet I’m still going to reload the page. Maybe my browser seems to have repainted the screen incorrectly, or I just want to be certain I have the very latest stock quotes.
APIs May Be Stateless, Human Interaction Is Not
Unlike an internal request via a RESTful API, a human user’s interaction with a web site is not stateless. As a web user, I think of my visit to your site as a session, almost like a phone call. I expect the browser to remember data about my session, in the same way that when I call your sales or support line, I expect the representative to remember what was said earlier in the call.

An obvious example of session data is whether I’m logged in, and if so, as which user. Once I go through a login screen, I should be able to navigate freely through the user-specific pages of the site. If I open a link in a new tab or window and I’m presented with another login screen, that’s not very user friendly.
Another example is the contents of the shopping cart in an e-commerce site. If hitting F5 empties the shopping cart, users are likely to get upset.
In a traditional multi-page application written in PHP, session data would be stored in the $_SESSION superglobal array. But in an SPA, it needs to be somewhere on the client side. There are four main options for storing session data in an SPA:
- Cookies
- Fragment identifier
- Web storage
- IndexedDB
Four Kilobytes of Cookies
Cookies are an older form of web storage in the browser. They were originally intended to store data received from the server in one request and send it back to the server in subsequent requests. But from JavaScript, you can use cookies to store just about any kind of data, up to a size limit of 4 KB per cookie. AngularJS offers the ngCookies module for managing cookies. There is also a js-cookies package that provides similar functionality in any framework.

Keep in mind that any cookie you create will be sent to the server on every request, whether it’s a page reload or an Ajax request. But if the main session data you need to store is the access token for the logged-in user, you want this sent to the server on every request anyway. It’s natural to try to use this automatic cookie transmission as the standard means of specifying the access token for Ajax requests.
You may argue that using cookies in this manner is incompatible with RESTful architecture. But in this case it is just fine as each request via the API is still stateless, having some inputs and some outputs. It’s just that one of the inputs is being sent in a funny way, via a cookie. If you can arrange for the login API request to send the access token back in a cookie also, then your client side code hardly needs to deal with cookies at all. Again, it’s just another output from the request being returned in an unusual way.
Cookies offer one advantage over web storage. You can provide a “keep me logged in” checkbox on the login form. With the semantics, I expect if I leave it unchecked then I will remain logged in if I reload the page or open a link in a new tab or window, but I’m guaranteed to be logged out once I close the browser. This is an important safety feature if I’m using a shared computer. As we’ll see later, web storage does not support this behavior.
So how might this approach work in practice? Suppose you’re using LoopBack on the server side. You’ve defined a Person model, extending the built-in User model, adding the properties you want to maintain for each user. You’ve configured the Person model to be exposed over REST. Now you need to tweak server/server.js to achieve the desired cookie behavior. Below is server/server.js, starting from what was generated by slc loopback, with the marked changes:
var loopback = require('loopback');
var boot = require('loopback-boot');
var app = module.exports = loopback();
app.start = function() {
// start the web server
return app.listen(function() {
app.emit('started');
var baseUrl = app.get('url').replace(/\/$/, '');
console.log('Web server listening at: %s', baseUrl);
if (app.get('loopback-component-explorer')) {
var explorerPath = app.get('loopback-component-explorer').mountPath;
console.log('Browse your REST API at %s%s', baseUrl, explorerPath);
}
});
};
// start of first change
app.use(loopback.cookieParser('secret'));
// end of first change
// Bootstrap the application, configure models, datasources and middleware.
// Sub-apps like REST API are mounted via boot scripts.
boot(app, __dirname, function(err) {
if (err) throw err;
// start of second change
app.remotes().after('Person.login', function (ctx, next) {
if (ctx.result.id) {
var opts = {signed: true};
if (ctx.req.body.rememberme !== false) {
opts.maxAge = 1209600000;
}
ctx.res.cookie('authorization', ctx.result.id, opts);
}
next();
});
app.remotes().after('Person.logout', function (ctx, next) {
ctx.res.cookie('authorization', '');
next();
});
// end of second change
// start the server if `$ node server.js`
if (require.main === module)
app.start();
});
The first change configures the cookie parser to use ‘secret’ as the cookie signing secret, thereby enabling signed cookies. You need to do this because although LoopBack looks for an access token in either of the cookies ‘authorization’ or ‘access_token’, it requires that such a cookie be signed. Actually, this requirement is pointless. Signing a cookie is intended to ensure that the cookie hasn’t been modified. But there’s no danger of you modifying the access token. After all, you could have sent the access token in unsigned form, as an ordinary parameter. Thus, you don’t need to worry about the cookie signing secret being hard to guess, unless you’re using signed cookies for something else.
The second change sets up some postprocessing for the Person.login and Person.logout methods. For Person.login, you want to take the resulting access token and send it to the client as the signed cookie ‘authorization’ also. The client may add one more property to the credentials parameter, rememberme, indicating whether to make the cookie persistent for 2 weeks. The default is true. The login method itself will ignore this property, but the postprocessor will check it.
For Person.logout, you want to clear out this cookie.
You can see the results of these changes right away in the StrongLoop API Explorer. Normally after a Person.login request, you would have to copy the access token, paste it into the form at the top right, and click Set Access Token. But with these changes, you don’t have to do any of that. The access token is automatically saved as the cookie ‘authorization’, and sent back on each subsequent request. When the Explorer is displaying the response headers from Person.login, it omits the cookie, because JavaScript is never allowed to see Set-Cookie headers. But rest assured, the cookie is there.
On the client side, on a page reload you would see if the cookie ‘authorization’ exists. If so, you need to update your record of the current userId. Probably the easiest way to do this is to store the userId in a separate cookie on successful login, so you can retrieve it on a page reload.
The Fragment Identifier
As I’m visiting a web site that has been implemented as an SPA, the URL in my browser’s address bar might look something like “https://example.com/#/my-photos/37”. The fragment identifier portion of this, “#/my-photos/37”, is already a collection of state information that could be viewed as session data. In this case, I’m probably viewing one of my photos, the one whose ID is 37.

You may decide to embed other session data within the fragment identifier. Recall that in the previous section, with the access token stored in the cookie ‘authorization’, you still needed to keep track of the userId somehow. One option is to store it in a separate cookie. But another approach is to embed it in the fragment identifier. You could decide that while I’m logged in, all the pages I visit will have a fragment identifier beginning with “#/u/XXX”, where XXX is the userId. So in the previous example, the fragment identifier might be “#/u/59/my-photos/37” if my userId is 59.
Theoretically, you could embed the access token itself in the fragment identifier, avoiding any need for cookies or web storage. But that would be a bad idea. My access token would then be visible in the address bar. Anyone looking over my shoulder with a camera could take a snapshot of the screen, thereby gaining access to my account.
One final note: it is possible to set up an SPA so that it doesn’t use fragment identifiers at all. Instead it uses ordinary URLs like “http://example.com/app/dashboard” and “http://example.com/app/my-photos/37”, with the server configured to return the top level HTML for your SPA in response to a request for any of these URLs. Your SPA then does its routing based on the path (e.g. “/app/dashboard” or “/app/my-photos/37”) instead of the fragment identifier. It intercepts clicks on navigation links, and uses History.pushState() to push the new URL, then proceeds with routing as usual. It also listens for popstate events to detect the user clicking the back button, and again proceeds with routing on the restored URL. The full details of how to implement this are beyond the scope of this article. But if you use this technique, then obviously you can store session data in the path instead of the fragment identifier.
Web Storage
Web storage is a mechanism for JavaScript to store data within the browser. Like cookies, web storage is separate for each origin. Each stored item has a name and a value, both of which are strings. But web storage is completely invisible to the server, and it offers much greater storage capacity than cookies. There are two types of web storage: local storage and session storage.

An item of local storage is visible across all tabs of all windows, and persists even after the browser is closed. In this respect, it behaves somewhat like a cookie with an expiration date very far in the future. Thus, it is suitable for storing an access token in the case where the user has checked “keep me logged in” on the login form.
An item of session storage is only visible within the tab where it was created, and it disappears when that tab is closed. This makes its lifetime very different from that of any cookie. Recall that a session cookie is still visible across all tabs of all windows.
If you use the AngularJS SDK for LoopBack, the client side will automatically use web storage to save both the access token and the userId. This happens in the LoopBackAuth service in js/services/lb-services.js. It will use local storage, unless the rememberMe parameter is false (normally meaning the “keep me logged in” checkbox was unchecked), in which case it will use session storage.
The result is that if I log in with “keep me logged in” unchecked, and I then open a link in a new tab or window, I won’t be logged in there. Most likely I’ll see the login screen. You can decide for yourself whether this is acceptable behavior. Some might consider it a nice feature, where you can have several tabs, each logged in as a different user. Or you might decide that hardly anyone uses shared computers any more, so you can just omit the “keep me logged in” checkbox altogether.
So how would the session data handling look if you decide to go with the AngularJS SDK for LoopBack? Suppose you have the same situation as before on the server side: you’ve defined a Person model, extending the User model, and you’ve exposed the Person model over REST. You won’t be using cookies, so you won’t need any of the changes described earlier.
On the client side, somewhere in your outermost controller, you probably have a variable like $scope.currentUserId which holds the userId of the currently logged in user, or null if the user is not logged in. Then to handle page reloads properly, you just include this statement in the constructor function for that controller:
$scope.currentUserId = Person.getCurrentId();
It’s that easy. Add ‘Person’ as a dependency of your controller, if it isn’t already.
IndexedDB
IndexedDB is a newer facility for storing large amounts of data in the browser. You can use it to store data of any JavaScript type, such as an object or array, without having to serialize it. All requests against the database are asynchronous, so you get a callback when the request is completed.
You might use IndexedDB to store structured data that’s unrelated to any data on the server. An example might be a calendar, a to-do list, or saved games that are played locally. In this case, the application is really a local one, and your web site is just the vehicle for delivering it.
At present, Internet Explorer and Safari only have partial support for IndexedDB. Other major browsers support it fully. One serious limitation at the moment, though, is that Firefox disables IndexedDB entirely in private browsing mode.
As a concrete example of using IndexedDB, let’s take the sliding puzzle application by Pavol Daniš, and tweak it to save the state of the first puzzle, the Basic 3x3 sliding puzzle based on the AngularJS logo, after each move. Reloading the page will then restore the state of this first puzzle.
I’ve set up a fork of the repository with these changes, all of which are in app/js/puzzle/slidingPuzzle.js. As you can see, even a rudimentary usage of IndexedDB is quite involved. I’ll just show the highlights below. First, the function restore gets called during page load, to open the IndexedDB database:
/*
* Tries to restore game
*/
this.restore = function(scope, storekey) {
this.storekey = storekey;
if (this.db) {
this.restore2(scope);
}
else if (!window.indexedDB) {
console.log('SlidingPuzzle: browser does not support indexedDB');
this.shuffle();
}
else {
var self = this;
var request = window.indexedDB.open('SlidingPuzzleDatabase');
request.onerror = function(event) {
console.log('SlidingPuzzle: error opening database, ' + request.error.name);
scope.$apply(function() { self.shuffle(); });
};
request.onupgradeneeded = function(event) {
event.target.result.createObjectStore('SlidingPuzzleStore');
};
request.onsuccess = function(event) {
self.db = event.target.result;
self.restore2(scope);
};
}
};
The request.onupgradeneeded event handles the case where the database doesn’t exist yet. In this case, we create the object store.
Once the database is open, the function restore2 is called, which looks for a record with a given key (which will actually be the constant ‘Basic’ in this case):
/*
* Tries to restore game, once database has been opened
*/
this.restore2 = function(scope) {
var transaction = this.db.transaction('SlidingPuzzleStore');
var objectStore = transaction.objectStore('SlidingPuzzleStore');
var self = this;
var request = objectStore.get(this.storekey);
request.onerror = function(event) {
console.log('SlidingPuzzle: error reading from database, ' + request.error.name);
scope.$apply(function() { self.shuffle(); });
};
request.onsuccess = function(event) {
if (!request.result) {
console.log('SlidingPuzzle: no saved game for ' + self.storekey);
scope.$apply(function() { self.shuffle(); });
}
else {
scope.$apply(function() { self.grid = request.result; });
}
};
}
If such a record exists, its value replaces the grid array of the puzzle. If there is any error in restoring the game, we just shuffle the tiles as before. Note that grid is a 3x3 array of tile objects, each of which is fairly complex. The great advantage of IndexedDB is that you can store and retrieve such values without having to serialize them.
We use $apply to inform AngularJS that the model has been changed, so the view will be updated appropriately. This is because the update is happening inside a DOM event handler, so AngularJS wouldn’t otherwise be able to detect the change. Any AngularJS application using IndexedDB will probably need to use $apply for this reason.
After any action that would change the grid array, such as a move by the user, the function save is called which adds or updates the record with the appropriate key, based on the updated grid value:
/*
* Tries to save game
*/
this.save = function() {
if (!this.db) {
return;
}
var transaction = this.db.transaction('SlidingPuzzleStore', 'readwrite');
var objectStore = transaction.objectStore('SlidingPuzzleStore');
var request = objectStore.put(this.grid, this.storekey);
request.onerror = function(event) {
console.log('SlidingPuzzle: error writing to database, ' + request.error.name);
};
request.onsuccess = function(event) {
// successful, no further action needed
};
}
The remaining changes are to call the above functions at appropriate times. You can review the commitshowing all of the changes. Note that we are calling restore only for the basic puzzle, not for the three advanced puzzles. We exploit the fact that the three advanced puzzles have an api attribute, so for those we just do the normal shuffling.
What if we wanted to save and restore the advanced puzzles also? That would require some restructuring. In each of the advanced puzzles, the user can adjust the image source file and the puzzle dimensions. So we’d have to enhance the value stored in IndexedDB to include this information. More importantly, we’d need a way to update them from a restore. That’s a bit much for this already lengthy example.
Conclusion
In most cases, web storage is your best bet for storing session data. It’s fully supported by all major browsers, and it offers much greater storage capacity than cookies.
You would use cookies if your server is already set up to use them, or if you need the data to be accessible across all tabs of all windows, but you also want to ensure it will be deleted when the browser is closed.
You already use the fragment identifier to store session data that’s specific to that page, such as the ID of the photo the user is looking at. While you could embed other session data in the fragment identifier, this doesn’t really offer any advantage over web storage or cookies.
Using IndexedDB is likely to require a lot more coding than any of the other techniques. But if the values you’re storing are complex JavaScript objects that would be difficult to serialize, or if you need a transactional model, then it may be worthwhile.
This post originally appeared in Toptal Engineering Blog